Whiz had a great post analyzing letter frequencies and pulling out some awesome seed words to use to boost your quordle scores. You’ll get no such help from me. Not only am I not qualified to give such advice (considering I flirt with the Tundra line most day), but I choose different seed words every day as they pop into my head.
No, this article will not be useful for you. It won’t be insightful. It’s a glorified science fair project, and the presentation quality will be on par with that.
I built a python script that I affectionately call “QuordleBot”. It takes in a solution and the wordlist Whiz used and plays quordle with the same information you and I have. It’s a test of strategy and technique. Yes, it can do things that we can’t (like count how many word possibilities there are for each quadrant), but it’s also limited in ways we aren’t.
[Insert Hype’s NERDS sign here]
QuordleBot outputs some interesting information after each guess. Under the hood, it keeps separate wordlists for each quadrant and synthesizes them into a master wordlist. After each guess, it displays how many words were removed from each quadrant’s wordlist and how many are left. You can start to see interesting patterns as you run QuordleBot a few times. The first seed word is very important, for example.
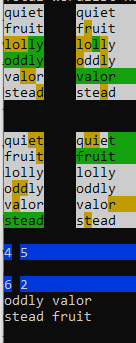
Here’s a representative run from QuordleBot for the May 24th Quordle:
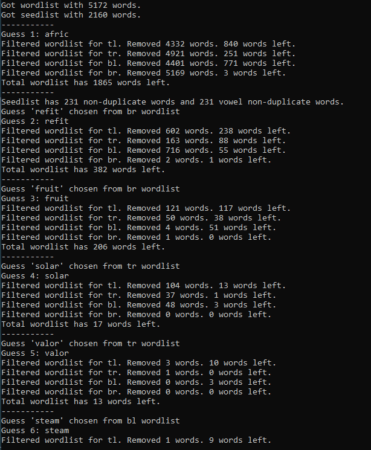
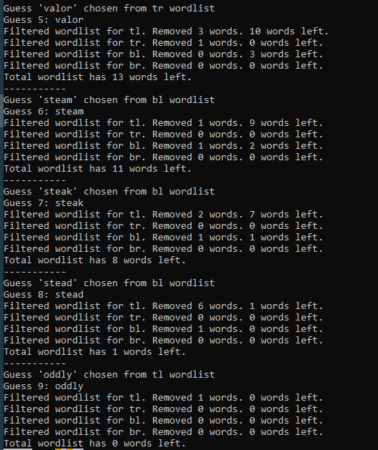
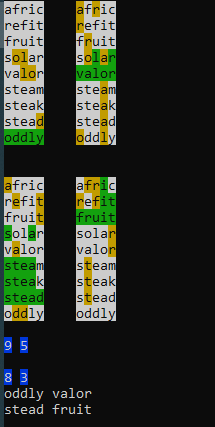
One thing to note about this is that the results are non-deterministic. It doesn’t get the same score every time it is run. This is mostly due to the random first seedword. From there the choices are dictated mathematically. Oddly enough, my successive runs for this post landed on the same exact score from different seed words. I ran it again to show that the scores can be different.
Anyway, all of this is great, but the interesting part is where I get to play with the guessing algorithm. Version 0.1 was just to test out the infrastructure (making sure it would display correctly and the like). It was a pure random guess from the 5100-some words in the wordlist. I have seen a few quadruple chumps, which makes sense because you’re picking 9 times from a hat filled with 5100 letters to find 4 words. I haven’t sat in a stats class in over a decade, but I know that the likelihood of not chumping is somewhere between pigs flying and Swiss not narrowing his gaze.
Clearly, some improvements were needed, and the obvious ones came first. Version 1.0 was still random word selection, but QuordleBot kept track of independent word lists for each quadrant and removed words when they were no longer viable. It then combined those lists into a single master wordlist and randomly chose from that list. This was a massive improvement. QB was no longer a guaranteed 2 chumper, but it was still a pretty bad quordle player. The seedword guesses were hot garbage, often including only a single vowel and letter duplicates. Single and double chumps were routine, and, more alarmingly, there were situations where QB knew the solution but wasn’t able to solve it. If, for example, bottom left had one word left in its wordlist, QB dutifully added that one word to the master wordlist and randomly selected a word from that list.
Version 1.1 improved the seedword problem. I had QB generate a seedword list of all words with certain characteristics. As of now, those characteristics are (1) no duplicate letters; (2) at least 2 vowels; and (3) vowels plus common consonants (tslnhrcp) must make up at least 4 letters of the word. This is probably a bit overbroad as it covers 40% of the total wordlist (you can see that there are 2160 seedwords according to the screenshot above), but I haven’t bothered optimizing the seedword list yet. Anyway, in version 1.1, QB randomly chose from the seedword list for guesses 1 and 2 before expanding to the whole wordlist for guess 3.
Version 1.2 tackled the “unable to solve” issue. I established a threshold (that can be tuned) where QB can override the random selection from the master list (or seedlist) to instead randomly select from a certain quadrant’s list. You’ll see that behavior in most of the guesses above where it says “chosen from tr [top-right] wordlist” or similar. The threshold can actually be tuned separately for a few different conditions. For guess 2, the threshold is much lower than for guesses 3+ so that we only override the default behavior if there’s a high likelihood of getting a word in 2. At this point, QB was an average quordler. Most scores were at or slightly above the Tundra line, but the teens were popping up on occasion and chumping had become blessedly uncommon. However, I did notice a glaring issue. When I’m using seed words in my first two guesses, I make an attempt to have them be as different of words as possible. QB wasn’t doing that. It was just randomly pulling the next word from the seedlist.
Version 1.3 experimented with generating a smaller seedlist after the first guess containing only words that had no overlap with the first guess. This was not successful, and I backed it off to a smaller seedlist containing only words that had no vowel overlap with the first guess. It took me a while to figure out why I was having trouble with this code…. quite often, the first guess eliminates so many words from the seedlist that there are none left that don’t overlap with the first guess. The solution was simple. Make it cascade from the no duplicate letters seedlist to the no duplicate vowels seedlist to the full seedlist to the full wordlist. If one is empty, move on to the next one. You can see in guess two where QB outputs how big those first two lists are. They’re the same size in this example, but that’s only sometimes the case. At this point QB was a fairly decent quordler, regularly scoring in the upper teens and low 20s. Now was the time for the big experiment….
Version 2.0 is the current version and it experiments with what I call “impact”. Impact is a measure of how many words a potential guess eliminates from the wordlist. Ah, but trashy, you idiot… unless you were to know the solution ahead of time, you’d have no clue how many words are eliminated by that guess. You must be cheating with this impact thing!
Well, no. Err, at least, not exactly. QB does something humans couldn’t possibly do as it would take us ages. Here’s how QB measures the impact of every single word in the wordlist:
(1) QB iterates through every possible (and many impossible) ordering of green, yellow, and gray squares for each potential guess word.
(2) For each ordering of colors, QB scans the entire wordlist and counts how many words would be eliminated if that was the result of the guess.
(3) The number of words eliminated is summed across all of the orderings and is used as the impact score.
(4) QB selects the word with the highest impact score to play as the guess.
This process has replaced random searching in every single decision branch except for one. Guess 1 is still random. This is due to performance limitations. Even guess 2 is rather slow (on the order of a minute) when the first guess wasn’t particularly good. If, for example, there were 200 non-duplicate seedwords left after guess 1 and 1000 total words left in the wordlist, impact scoring all of the non-duplicate seedwords will result in the code running in a loop 200 (non-dup seeds)*3^5(number of orderings)*5(number letters that have to be compared)*1000(words to be compared to) = 243,000,000 times, which takes a bit of time. By the time you get to guess 3, the sizes of the lists you’re working with are small enough that it usually takes fractions of a second to calculate the impact scores (of course, right after writing this, I did a run for fun and it hung on guess 3 for reasons not worth explaining).
The impact score method has reduced the number of runs where QB struggles to sneak in the last word in guess 9 or ends up chumping, but I’m not sure that it helps with getting an earlier start on solving. Us humans tend to be able to rattle off 3 or 4 in a row as the letters start to fall into place. QB gets stuck guessing some weird esoteric words that are probably not in the quordle list, and the result is a whole lot of 3 -> 5 -> 8 -> 9 scores.
Next steps for me are to take this in a few directions. First, I want to optimize the algorithm for calculating impact by removing the impossible (e.g. 4 greens and a yellow) and irrelevant (e.g. 5 greens) cases from the calculations. Second, I want to introduce some randomness back in to the process by having QB do a weighted selection between the top X guess candidates by impact. Finally, I want to find a way to introduce commonness of the word into the equation. My intuition has been that the more common word is the right answer most of the time, and I want to give QB that same intuition.
If any of you [insert Hype’s NERDS sign here, too] want to tinker with the code, you can access it here:
https://gitlab.com/glibertarians/QuordleBot
Feel free to pull a fork or request edit permissions and add a branch to the project.
All those bare constants….
/shudder
Geek porn! Thanks Trashy!
I was wondering how you did your bot. I started to build one in VBA and then decided it would be a good exercise to teach myself Python, so I’m working on that, but way way behind you.
Working on a C# version….this could get interesting in the battle of algorithms
I’m working on the LGBTQ version. Written in LISP.
Can the words identify as correct?
They can, but its a moving list
LISP _is_ pretty gay.
Waiting for Deadhead to drop his Rust version that runs in 500 milliseconds
You kids and your “fancy” programming languages.
We had to learn Fortran 77 in engineering school.
Why? Because that’s what the ancient professors knew how to teach.
Harumph! You kids and your fancy, dancy, modern programming.
FORTRAN IV!
You never programmed a Jacquard loom?
I am disappoint.
Who hasn’t?
In 1968 I programmed in a crude machine language (no acronyms, just numbers) on a computer with a grand total of 400 Bytes, including all of the code and data storage. Input was with paper tape.
You guys are honing your programming skills, and I’m just hanging out by the pool editing high speed video of a 415 kilojoule capacitor (fully charged) blowing up for use in a safety course I’m creating.
I’m more of a HULK SMASH kind of nerd.
Do we get to see it go boom? Or is it crackle-Boom?
high speed video of a 415 kilojoule capacitor (fully charged) blowing up for use in a safety course I’m creating.
That doesn’t sound very safe. But it does sound like fun!
Trust me, we were well away and in a bunker! We introduced the fault remotely; the cap took care of the rest.
*Imagines HE with a sniper rifle, shooting the capacitor.*
It was a young Marine vet whom I’d hired (for his mechanical engineering skills) and who happened to have been a sniper in Iraq. He hit the bullseye with a .50 cal from about 100 yards.
It was…spectacular.
You joke but we had a transportainer with spare capacitors that got damaged by a forest fire in 2000. Knowing that the safety wires were probably melted we devised a scheme to drive a spike through them.
Stored energy is no joke.
I wasn’t joking about the boom. And my guess was pretty close.
We had oversized barrels of conductive water nearby and the caps all prerigged to be fork trucked into the barrels so that any remaining charge would short out.
There were many muffled booms as the water penetrated in.
That was a trick I learned years ago when we had to improvise by blasting a bad cap with a shotgun an tipping it into a horse trough.
This was much better planned.
Eh, just use an uninsulated screwdriver to short the terminals.
/I’ve never done that
You would have been consumed by the conflagration!
We did have a scare where we had a capacitor (a big one) that had shorted internally to the case. Both HV+ and HV – were supposed to be floating front windows case. But because the case was in contact with one of those voltages, touching a conductor to either terminal and the case would cause a short
All we knew was that something was wrong, so two guys suited up with full arc flash gear (spacesuit looking stuff)- and went over to short it with two grounding sticks. Well, bringing the stick over to the terminal was close enough to the case to flash over. Big time. Both guys were protected by their gear, but suffered temporary hearing loss. One resigned a month later.
I changed the protocol after that scare.
“Floating from the case”
Front windows case? No idea.
I’ve only done it on small size caps, just in case it wasn’t really fully failed, before replacing. Those things still bother me. Come to think of it, I think I left one bypassed in my old job and never got around to changing it.
At a previous job we had to figure out how to explode a main landing gear tire in its retracted state for a test. Nichrome wire hooked up to a huge (several farads) capacitor bank eventually did the trick. But we had to do many experiments before that to dial it in. Nichrome wire drilled through a softball – the leather cover went sideways at a high rate of speed, the rest of the ball hit the 3 story ceiling. It was decided that maybe we should have a plexiglass cage around the next test article.
Pressure vessel go SUCK!!
https://www.youtube.com/watch?v=0N17tEW_WEU
Q: How did your tank trailer fail?
A: Gradually, then all at once.
Pretty impressive!
One advantage of pulse power: find the debris and look up. Most of the time the failure is obvious. It’s the other time that we earn our bucks.
Pulse power is the most pure example of physical laws that I know of. When I was trying to pick a career I thought that I would like to harness lightning. Sometimes dreams can come true.
This linear accelerator creating an electron beam is nuts. I just work on the pulsed power side, but the physicists work on the beam itself. However, it’s kind of hand-in-hand so I’m having to learn new tricks.
Pure physics is very true. Lots of terms no longer completely drop out with the extremes we work with. The electron beam we send down the pipe is “near relativistic” as they say.
“You never visit”
/Electron beam
Please share!
Seconded! If it’s permitted to be shared to the public, I’d like to see that.
she’ll have to blur out the Greys standing in the background first.
I DIDNT SEE NUFFIN’ !!
It’s considered proprietary. 🙁
Maybe I can get cool footage of something else this summer that I can share. Our interns are here, and we are thinking of doing something fun in addition to their work.
I used to work at a power plant. We had 3 units, each about 850 net MWe. The main buses, from the generators to the step-up transformers, had solid copper bus bars in air conditioned ducts–about 400 feet of bus bar between the generators and the GSUs.
One day, somehow, some water got in one phase of one of the units’ bus bars while the unit was at full load. Fully 60 feet of solid copper immediately went from solid to gas. That was a lot of damage.
Copper expands about 64,000 times its original volume when it goes from solid to plasma. It pretty much skips liquid and gas and goes straight to ionized gas, happily carrying tons of current until it finally snuffs out.
I’ve inhaled more copper than is probably healthy…
Can I see your photon torpedo when it’s finished?
Phrasing?
The important question is – can quordlebot First? It cannot, can it?
Bro’s Firsting theme song
What was the source of the wordlist? What is the possibility of words from the official list not being on it?
I would assume all 5-letter words are on the list.
There are different lists of words (and hence 5-letter words) on the internet, some with many more obscure words (and some that are suspect as actual words, IMHO, and that are not recognized by Quordle). It sounds like Trashy used something like the list I used (from UMichigan), given the number of 5-letter words in his list.
Trashy encouraged me to find the actual Wordle list of 2300+ 5-letter words, from which supposedly Quordle words are chosen. I have done so and will update my analysis at some point. The two key differences between the Michigan list and the Wordle list are that the Wordle list has only fairly common words (for the most part) and doesn’t seem to have plurals (like JUMPS). That changes the likelihood of where in a word the letter S shows up.
I’m glad you found the Wordle list. Is it actually the same at the Quordle list, though? Obviously we see words on the Q list at 4X the rate, but double letters words seem much more common in Q’ than W’.
I don’t know.
NERD!!!!
Seriously, nice work, trashy! In my copious spare time I’ll have to check out a branch and play with it
So, how about them Bears?
* lights Jesse signal *
Technically speaking, big hairy men having sex with each other is less gay than quordle.
I cannot find a proper quip to this…
I believe he is talking himself into accepting his homosexuality. We should support him.
I thought that was the definition of “Quordle”
Jesse has become as rare as Bigfoot around here.
He’s in good company.
Interesting write-up on the quordle bot. Do you have any learning going on from game to game?
I’m trying to put together a document for an audience I don’t know, trying to convey information whose scope I don’t understand, and if I phrase it wrong, it could be used against us to avoid work they’ve been contracted for.
I’m staring at one of my potential sources of information which ends with a slide that says “Questions?” and has clip art of a generif figure scratching their head while leaning on a question mark. I can relate to the clip art dude.
I love management.
Ah! That’s why you phrase it in such a way that contractor will certainly be able to meet the language.
(whether or not they deliver a viable product or result is secondary)
/FeelYourPain
A common tactic contractors use with us is to act like the statement of work has State staff doing work that we’re paying the contractors for.
One didn’t even pretend and submitted a statement of work which was “state staff will implement…”. In that one, we decided to just not hire them and while state staff did implement the project, the contractor didn’t get any money.
So your contractors are the ones that submit SoW? Where I am, it’s us that create the SoW, which (along with many other docs) is what generates the Request for Proposal, which is what actually goes out for bid.
However, there’s far too much “oh, ya, that’s not in our scope” shenanigans during the execution where we’re having to quote the very contract they were awarded to get them to get it done.
More frustrating to me are the contractors that claim expertise, get the award, only to then desperately try to find a subcontractor that actually has the expertise…
For us the SOW is a negotiation.
I don’t know exactly but it may bounce back and forth during negotiations, with each side proposing edits to the SoW. But the “You do all the work and pay us” proposal came from the contractor.
That last one is common. They are also the ones that always bid low.
Gotcha. Ya, negotiations can happen, but only once there is an actual winning bidder, essentially.
I think my favorite are the projects where we’re paying the contractor to fix the product that they delivered broken the first time, but that technically met the letter of the contract.
I have a good shell of the document… which was due last week.
I haven’t gotten the staff trained up to handle the production issue from mid-may, so I got drawn away from these management paperwork tasks. So much knowledge transfer, so many other tasks to do.
I sent in my bumbling attempts at a good enough document.
I want to call out tomorrow, but I have meetings that have relevance for future plans, so I gotta show up at least to those.
Fun.
Clip art on a slide-show, the 90s lives on!
Oh, come on, we just got out of the 70s by retiring the mainframe last year.
Imagine openly bragging about bringing about the end of Man’s dominance over Machine.
I didn’t like The Matrix III either.
Meanwhile, I’m learning how to score high school kids’ standardized test essays. New gig. Thanks, @Pontiff!
Congrats on the job.
How do you like it so far?
I’m only 4 hours into it and it’s training so… not sure? Seems pretty straightforward.
Well, good luck. Hope it goes well.
It’s just a part-time temp thing. I don’t keep all my eggs in one or two or three baskets, but that has its downsides and that’s juggling all those baskets.
I understand.
I’m in the opposite boat – one big basket full of eggs and stress.
Interesting. I did TOEFL evaluations for a couple years. Very weird what some people think is coherent thought.
I just did a training set and … I’m a harsh grader. Oopsie.
Harsh, but fair? Seems right.
Is there a “git gud noob” feedback option?
No, just a 0, 1, 2, or 3. I could zip through these all night.
Depends on what “harsh” means. For me, I’d let a lot of poor writing slide. It’s the circular arguments that drove me nuts.
Well, it’s important to write logically because logic is an essential part of writing.. 😛
But ya, when I’ve edited (for that level of writers), I’m more interested in their ability to put together thoughts that flow and transition (logically more than syntactically).
There still is some threshold when the quantity of basic grammar, spelling, and punctuation errors becomes it’s own quality, too.
Why ask why?
Because it’s the most important question, as demonstrated by the fact that all other questions are less important!
…drink Bud Dry.
…try Bud Dry.
You identify as a Scantron™?
Dude, that triggers me from my BYU testing center days.
https://www.leadfast.org/blog/2017/8/25/test-scoring-pencil-roundup
Oh how funny! That’s awesome.
Confession, I own a box of one of the pencils mentioned but haven’t used them yet. I love good quality pencils and keep a half dozen sharpened on my desk for making notes and what not during the day.
This is identical to the one I have on my desk, except mine is a little older.
https://youtu.be/YtLqbrVSgT0
Seconders write in pencils. People who are afraid of making mistakes. People who don’t take chances. People who can’t First.
That’s cool, Trashy. I would think that if you used higher-frequency seed words, such as some of the combos I found, it might improve QBots results.
Oops, “QBot’s”.
I would think QBot is the entity who is making Q’s selections every day. Surely he doesn’t have time to appraise them himself.
Do I even wanna start this quordle thing? *shrug*
Anyway, the aircon repair shop called me this morning. I told them to hold on and went downstairs to hand the wife the phone. She puts it up to her ear and says, “Moshi, moshi”
Evidently, I should’ve told her it was on speaker mode. Or not. Dude blasted out her eardrum.
And that’s how Straffinrun came to sleep on the couch.
She let him into the house after he forgot his keys again? I guess she wasn’t that mad.
Euphemisms. Sheesh.
#metoo
Thanks for dropping the code; I’d like to take a look at it.
Before I took a hiatus, I coded a little helper utility to shuffle the possible letters for me since my brain needed the assistance – not based on word lists or anything, just as a visual aid. It did help me a couple times. Nothing this fancy, though.
Follow-up from last week or so: non-working AC in the car was a hole in the condenser.
*grumble* pay several hundred to get it replaced.
Uh, still not working – compressor refuses to signal the ECU that there’s coolant in the system, even though there is. So, let’s replace the compressor that was replaced in 2018.
Working now, a cool grand later. On a 2009. My mechanic didn’t charge me labor for the compressor, which was nice.
On the plus side, I realized the KBB value has jumped from around $2,600 a couple years ago to over $6,000 now. Crazy times.
Good job playing the car market. You could get rich writing a newsletter.
My girlfriend’s buddy’s camper had a tree fall on it during the last wind storm (EF-1 tornado in some places). The insurance company decided to total it. They paid $8,000 for it a few years ago (used). Prices on campers have risen sharply recently. They used their insurance payout to buy a bigger used camper (with 4 different slide-outs) for $24,000 and spent the rest on tree removal.
????
??
Missed that – nice, Nick, nice.
Fast. But nice.
MikeS, we’re hearing the same music. PONick will no longer be POed and will be a regular life o’ the party guy at HH. Hoping we have a chance to meet the lady after a backseat ride from Doloot on one of Nick’s machines.
A good article with a warning for progs about what happens when they realize their dreams. Of course, they won’t read it.
https://www.aier.org/article/freedom-stands-above-everything/
With some exceptions, AIER has been a bastion of light for the past 2+ years.
Another good example here, thanks.
I especially liked:
My mind immediately went to Babylon 5, where the Psi Cops were told “The Corps is Mother, the Core is Father.”
No spoilers!
JK. I’m S02E05. Loving how every episode is more questions than answers.
Heh, the episode with that title is in S5, but I believe that the phrase (and certainly the concept!) was established early on.
And, IIRC, you’re just about to get into the place where B5 hits its stride. There are still a few ‘filler’ episodes, but by and large every one moves the arc forward.
Now I need to re-watch. So good.
The View from the Peanut Gallery is one of the worst episodes of sci-fi TV ever.
Change my mind.
*taps watch* Pick up the pace!
I have a strong feeling JMS knew his history when he wrote that.
Harlan Ellison was a grade A ass, but he could write and knew his history too.
GL gets it.
“your soul belongs to Jesus but your ass belongs to the corps”
Unrelated, but I figured you’d approve:
I’m doing this in about two weeks:
https://www.12metre.com/
AWESOME! We need pictures and a report.
DAILY QUORDLE ROUNDUP™©®
(The ’13!’ Edition)
#133
Champ
Not Adahn 13
whiz 20
Ownbestenemy 21
Sean 21
Tulip 21
MikeS 22
Ozymandias 22
rhywun 22
grrizzly 23
Mojeaux 23
TARDis 23
The Hyperbole 23
Grosspatzer 25
one true athena 25
robc 25
Ted S. 26
Tundra 26
Cannoli 28
Grummun 28
JG43 28
l0b0t 29
Chumps
db 115
Grumbletarian 118
kinnath 208
This is tied for the most on-topic DQR™©® ever. Too bad most of us do not deserve the honor…
After multiple people recently got the second lowest score possible, today Not Adhan went the other way and got the 4th highest possible score. Sure, he got lucky with his 1️⃣, but he then followed it up with a 3️⃣4️⃣5️⃣. Very nice Quordling!
The rest of you suck. Even with NA doing his best to raise the average, it was a pathetic 39.86. Kinnath pulling a MikeS obviously had a lot to do with it, but he wasn’t the only one who underperformed today. The T-line split of 8/16 tells the story. The other numbers…Quordlemetrics: 0 1 2 11 (2). Scrabble: 32
In Quorney news, Grosspatzer advanced to the finals to
put downtake outbeat The Hyperbole tomorrow. I know I speak for the entirety of the civilized world when I say to Grosspatzer (do you mind if I call you Arsenal?)…That’s all, folks. Gotta catch you later
13? WTF
Right?
My seed words are a matter of Glibs record. Which means if I post a 1-3, people know automatically one of the words.
Wait, I thought Gross and Hype played off today. Or was Gross in a playoff? I need to know when I’m playing the winner!
Gross’ and Gumble’ were in a tie breaker today. Gross’ won.
I just realized I transposed the words “lowest” and “highest”. Not sure if nobody jumped me for it because everyone understood what I meant, or because nobody reads them.
Not to whine, but I know I posted mine in the overnight Glibfit thread. As a reply to the 13 champ, so maybe you were too stunned to register it?
Sorry I missed you. I will rectify my oversight.
Forgot who I was talking to about Eudaimonia a couple months ago on a zoom. Tom Woods has great explanation of it today. https://tomwoods.com/ep-2139-aristotle-on-how-to-live-a-good-life/
Colorado just closed out the series.
Guess I picked the right team to carpetbag. Dang, what a game.
Sheesh. Meanwhile the Rangers are gonna have to slug it out with TB to 7 games – again. If they win.
I think it’s Rangers/Avs. Which is fine. Tired of Tampa.
This is really cool, trshy. It intrigues the hell out of me. As the day has gotten long, I will check this out tomorrow. It would be fun to run it on my own PC. As a super-non-programmer*, I may need some help with that. Will beg for assistance later.
*I can make a CNC mill, or lathe, or laser do WTF I want, but G&M Code is basically niche BASIC.
I haven’t written code since 1994. I have no interest in starting back up.
I’m having lunch tomorrow with an ER doctor. What questions should I ask about the Chicomvirus and the mandates taken to “prevent the spread” and get vaxxed?
Enjoy the veal and tip the waitress.
Night, Glibs. I gotta get some sleep.
Dare to First.
TFW never is the right time. 0% on a 10 year. FFS.
https://japantoday.com/category/business/update1-monetary-tightening-not-suitable-at-all-boj-chief-kuroda
I’m drunk and screaming out my windows at the drag racers.
It’s not like I can fucking go to sleep.
Sorry.
Maybe a silly question, but earplugs? Or noise-canceling earbuds?
Took me a few days or a week to get used to contoured earplugs, but makes a HUGE difference, especially when traveling.
Of course, certain frequencies go right through, so may not help in your case.
Of course, I have earplugs. The other day I discovered they work nicely during the regular blasting of shitty Arab techno music from I guess a nearby cafe when I wanted a Saturday afternoon nap.
I hate wearing them, though. Then I have to hear myself breathe.
But my main bitch is the general coarsening of “the culture” – the lack of common fucking courtesy, yes even here in NYC. It wasn’t like this even five years ago.
I can get that. Sorry ya gotta put up with it.
It’s not just NYC. I see it around here. Spitting in public, trash and litter including tossing it out of cars, walking around with music blaring out of speakers, etc.
The cars seem louder too. I dunno if it’s wider availability of aftermarket mods, original manufacture designs, or driver caused.
Loud diesel exhausts and booming systems are en vogue in my area. It straight up sucks.
Remind me why you continue to live in NYC?
You need a HOA, or a suppressed rifle.
This is very lazy grifting. Even politicians do a better job of hiding it.
https://twitchy.com/brettt-3136/2022/06/06/coalition-of-trans-organizations-calls-for-straight-white-americans-to-pay-cash-reparations-to-trans-people/
Where do I send the check?
Morning Glibs.
https://philadelphia.cbslocal.com/2022/06/06/south-street-mass-shooting-suspects-quran-garner-rashaan-vereen/
Oh, they actually arrested people. I’m shocked.
Expect this story to disappear fast.
Why are the FBI and US Marshalls involved? I can see the ATF for tracing guns (yeah, yeah, abomination that shouldn’t exist but it does), but the FBI and US Marshalls?
NJ primaries today.
I’d make a joke, but I live in PA. ?
https://patch.com/new-jersey/paramus/bergen-republicans-vie-unseat-tedesco-commissioners-election-2022
“Republicans Todd Calguire of Midland Park and Linda T. Barba of Fort Lee have filed to run against Tedesco, a Democrat.”
I’ve been getting daily annoying robocalls from Todd. “Vote for Caligula!” No thanks.
https://ktla.com/news/local-news/l-a-councilman-proposes-banning-camping-near-city-libraries/
“Camping”
Is it really camping if you’re inside city limits?
https://youtu.be/G3LvhdFEOqs
?
https://www.thegatewaypundit.com/2022/06/nude-hunter-biden-recklessly-brandishes-firearm-prostitute-leaked-video-joe-biden-demands-gun-control-law-abiding-americans/
Oh…Wednesday is gonna be lit…
Sometimes I wonder if Hunter is secretly a Glib.
Though, I think a Glib would know to keep his finger off the trigger.
https://thehill.com/changing-america/well-being/prevention-cures/3513474-menthol-flavored-cigarettes-may-lead-to-increased-smoking-among-teens-study-finds/
What’s the minimum age for smoking again? Laws do what, exactly?
Mornin’ all. Time for the gym.
Daily Quordle 134
3️⃣5️⃣
7️⃣4️⃣
quordle.com
4️⃣6️⃣
5️⃣7️⃣
I left Patzer some breathing room.
*takes deep breath*
Hail Mary on turn 3 after seeds were a complete bust.
Daily Quordle 134
7️⃣6️⃣
4️⃣3️⃣
quordle.com
Well played, good luck against whiz.
I have no chance. Chess, anyone?
Chess Pie?
Chess.
https://m.youtube.com/watch?v=csPoApTI93g
Why not ?
Daily Quordle 134
5️⃣4️⃣
7️⃣3️⃣
A nice little tune-up for tomorrow. Seed words worked well. Needed one extra guess to pin it down.
Daily Quordle 134
6️⃣4️⃣
7️⃣5️⃣
quordle.com
⬜⬜⬜⬜⬜ ⬜⬜⬜⬜?
⬜?⬜⬜⬜ ⬜?⬜?⬜
??⬜⬜⬜ ⬜⬜⬜⬜?
⬜?⬜⬜⬜ ?????
⬜???? ⬛⬛⬛⬛⬛
????? ⬛⬛⬛⬛⬛
⬜⬜⬜⬜⬜ ⬜⬜⬜⬜⬜
⬜⬜⬜⬜? ⬜?⬜⬜⬜
⬜??⬜⬜ ??⬜⬜?
⬜⬜⬜⬜⬜ ??⬜⬜⬜
⬜?⬜⬜⬜ ?????
⬜?⬜⬜⬜ ⬛⬛⬛⬛⬛
????? ⬛⬛⬛⬛⬛
The seed words giveth, the seed words taketh away.
Daily Quordle 134
3️⃣4️⃣
7️⃣5️⃣
quordle.com
Rota Fortuna swings upwards.
Daily Quordle 134
3️⃣5️⃣
7️⃣2️⃣
quordle.com
⬜??⬜⬜ ?⬜?⬜⬜
⬜???? ?⬜?⬜⬜
????? ⬜⬜?⬜⬜
⬛⬛⬛⬛⬛ ??⬜⬜?
⬛⬛⬛⬛⬛ ?????
⬜?⬜⬜⬜ ???⬜⬜
⬜?⬜⬜⬜ ?????
⬜?⬜⬜⬜ ⬛⬛⬛⬛⬛
⬜⬜⬜?⬜ ⬛⬛⬛⬛⬛
⬜⬜⬜⬜⬜ ⬛⬛⬛⬛⬛
??⬜?⬜ ⬛⬛⬛⬛⬛
????? ⬛⬛⬛⬛⬛
#waffle137 4/5
?????
?⭐?⭐?
?????
?⭐?⭐?
?????
? streak: 11
? #waffleelite
wafflegame.net
Nice! Ignatius Reilly approves.
He is my spirit animal. Forward the Crusade for Moorish Dignity!
I am picturing you in a certain fictional event which occurred in New Orleans. Onward Sodomites!
“’Oh, Fortuna, blind, heedless goddess, I am strapped to your wheel,’ Ignatius belched, ‘Do not crush me beneath your spokes.’”
suh’ fam
whats goody
Good morning, homey, l0, Tulip, DEG, Sean, & Stinky!
With any luck today at work will be less hectic than yesterday. The good news is that my boss took a turn working on payroll this week – he’s my backup and wants to be sure he’s up to speed so he can fill in for me after Fourth of July, allowing me to take that week off to attend SP’s memorial (assuming it happens then as tentatively announced.) Of course, part of what kept me so busy yesterday were his repeated questions about the details of the payroll process. All that’s left today, though, is final review and approval.
I’m lucky to have a good boss, even if we drive each other crazy on a regular basis.
Good morning to you. You do indeed have a good boss. His willingness to ask questions, better yet, his acknowledgement that he doesn’t know it all is refreshing.
It is now scheduled for July 30th.
Thank you! Was this announced somewhere here on the site or in a Forum, or did it come up during a Zoom?
I think zoom. I’ll suggest it be posted somewhere.
Please do, because zoom does not reach everyone who wants to pay respects.
It warms my cold, twisted heart to hear how many folk will be there. SP was an amazing women who touched the lives of so many people.
Mornin’, reprobates.
Good morning, ‘patzie! ?
Mornin’! There is a grey catbird nesting nearby, and I am apparently too close for comfort. I’m beginning to feel like a character in a Hitchcock film.
In its seat, no doubt, so you must respect that. ?
I just read the linked piece about Hunter’s firearm/prossy adventure pics and now , even over my tinnitus, I hear nothing but UNTZ… UNTZ… UNTZ… UNTZ…
The scab ridden legs on his lady are icing on the cake.
Hey- thats no lady!
Morning, Glibs.
Good morning, U! ?
The difference between sleeping in and oversleeping is whether you need to be up for something.
This morning, I overslept.
Its storming here, go back to bed.
Oops! I hope you weren’t late for any meetings. (It’s too early for meetings anyway!)
I haven’t missed any, but I had to crawl directly from bed to my computer to log into work.
Hope you were able to duck away long enough to grab a Dew.
Good Morning to all, had the first cuppa, ready to wreak havoc on my tiny little piece of earth.
Last night about 7 PM I got a load of concrete chimney blocks. Looks like the contractor is finally getting serious about repairing the winter damaged chimney. Insurance payment was generous so I’m feeling good about that part. It really isn’t a big job, only insurmountable for me and hard to find someone to do a small job.
Insurance payment was generous
Excellent!
Daily Quordle 134
4️⃣6️⃣
8️⃣5️⃣
quordle.com
I am weak.